Overview

Overview of the framework, using the dishwasher loading problem as a case study. Note that the non-leaf nodes in the Hierarchical Task Tree (HTT), the language descriptions of sibling tasks, and the flat specifications are color-coded to indicate one-to-one correspondence.
The HTT tree is structured such that it unfolds level by level, where each child task is a decomposition of its parent task. Notably, the tasks at the bottom level are not necessarily indecomposable. This flexibility allows for varying numbers of levels and tasks per level, accommodating differences in task understanding and the range of primitive actions available to robot agents.
Additionally, it's important to highlight that the relation $R$ specifically captures the temporal relationships between sibling tasks that share the same parent. The temporal relationship between any two tasks in the tree can be inferred by tracing their lineage back to their common ancestor, thereby simplifying the overall complexity of the structure.
When a task instruction is received, we use LLMs to construct the HTT through a two-step process, as outlined in step 1.
- Logical search: For every non-leaf node $v$, we gather its child tasks $V'$ and the temporal relations among them, defined by $R' \subseteq V' \times V'$. We then use LLMs to rephrase these child tasks and their temporal relations into syntactically correct sentences aligned with the semantics of LTL specifications (as illustrated in step 2.1). These reformulated sentences are input into a fine-tuned LLM that produces a single LTL formula (as depicted in step 2.2).
- Action Completion: Given an HTT, each leaf node should represent a simple task on certain object, such as "task 1.1.1 place plates into the lower rack" in example. By viewing such simple task as a sequence of action steps, we prompt the LLM to generate a sequence of pre-defined API calls to expand the simple task. For instance, the symbol $\pi_{\text{plates}}^l$ that represents task 1.1.1 can be replaced with LTL specification composed of sequential APIs (step 2.2): $$\pi_{\text{plates}}^l = \Diamond ( \texttt{Pickup(plate)} \wedge \Diamond\, \texttt{Move(plate, lower_rack)})$$ After this step, a complete hierarchical LTL specifications is generated (example in step 2.1).
AI2-THOR experiments
To evaluate our method on tasks with more complex temporal requirements, we combine several base tasks in the The ALFRED dataset to generate derivative tasks (each derivative task can be composed with up to 4 base tasks).
We compare our method with SMART-LLM. SMART-LLM uses LLMs to generate Python scripts that invoke predefined APIs for the purposes of task decomposition and task allocation.
The metrics are as follows:
1 base task with 4 robots: Place a computer on the ottoman
1 base task with 4 robots: Pick up a green candle and place it on the countertop
4 base tasks with 1 robot in dinning room
4 base tasks with 4 robots in dinning room
4 base tasks with 4 robots in bedroom
Real-world experiments
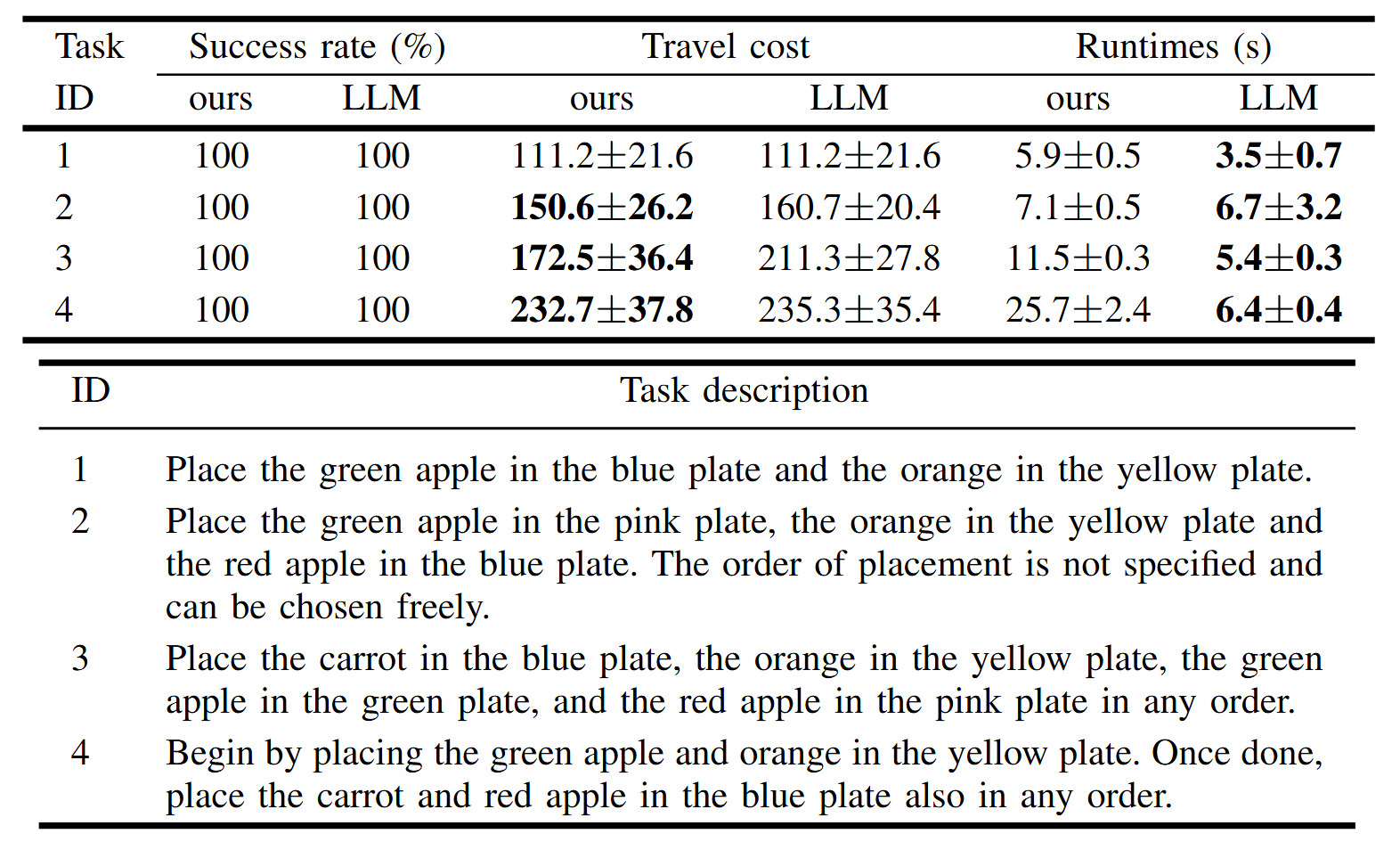
Our real-world experiments are conducted in a tabletop setting, where the task involves a robotic arm placing fruits and vegetables onto colored plates.
Given the primarily 2D nature of the task, we convert the tabletop environment into a discrete grid world. The use of only one robotic arm simplifies the task compared to the multi-robot scenarios in the simulator, as it eliminates the need for task allocation.
Our evaluation focuses on two main aspects: